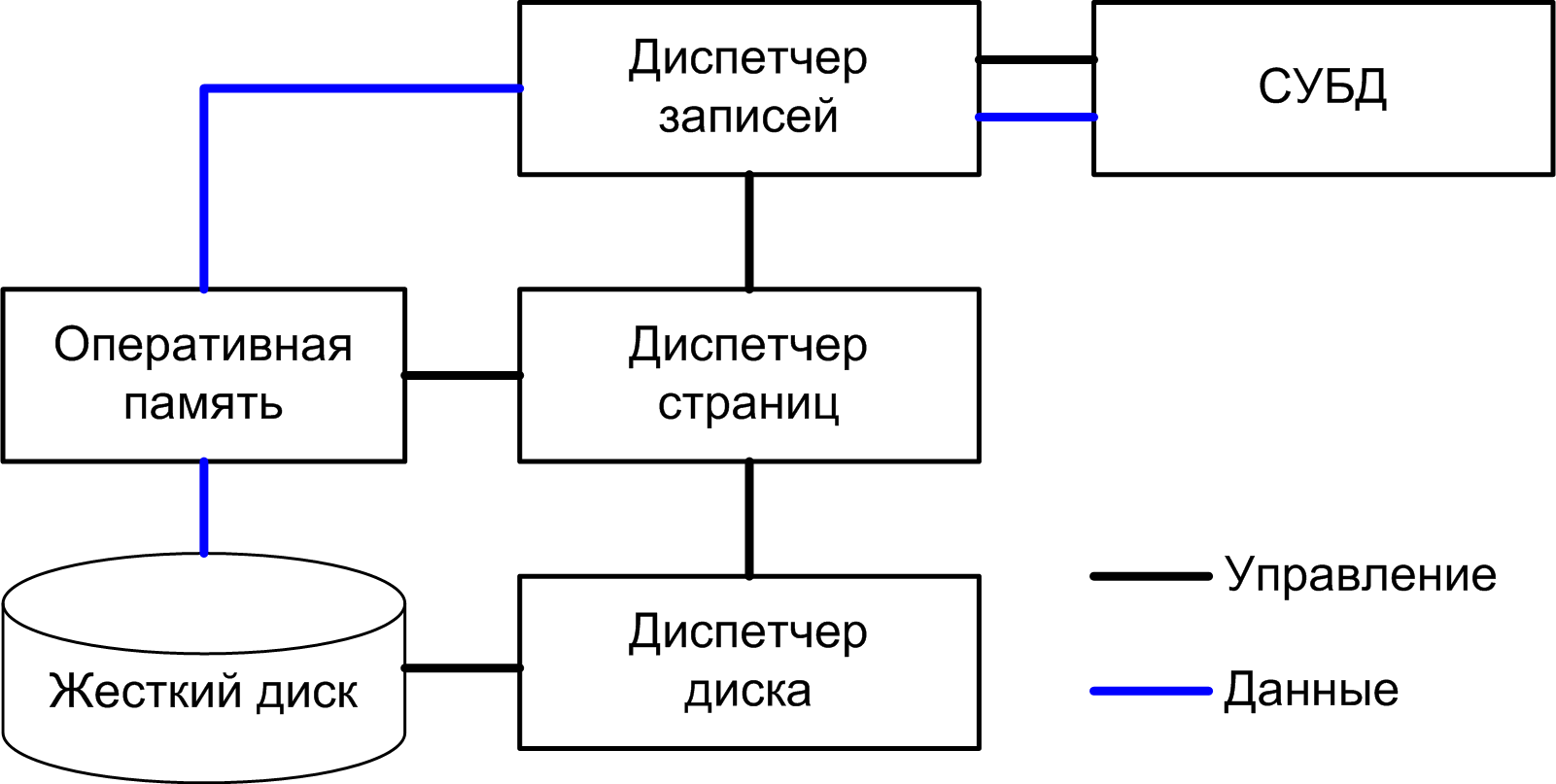
Базы данных
Хранение данных и индексирование
| Тип | Характеристика | Величина |
|---|---|---|
| Оперативная память | Объем | 16−256 ГБ |
| Цена | ~2-3 $/ГБ | |
| Быстродействие | ~100+ ГБ/c | |
| Время доступа | 1−10 μ/c | |
| SSD | Объем | 1−16 ТБ |
| Цена | ~0.1 $/ГБ | |
| Быстродействие | 0.500−6 ГБ/c | |
| Время доступа | 0.1−0.2 мс | |
| Жёсткие диски | Объем | 4−20 ТБ |
| Цена | 0.03 $/ГБ | |
| Быстродействие | 10−200 МБ/c | |
| Время доступа | 5−100 мc |
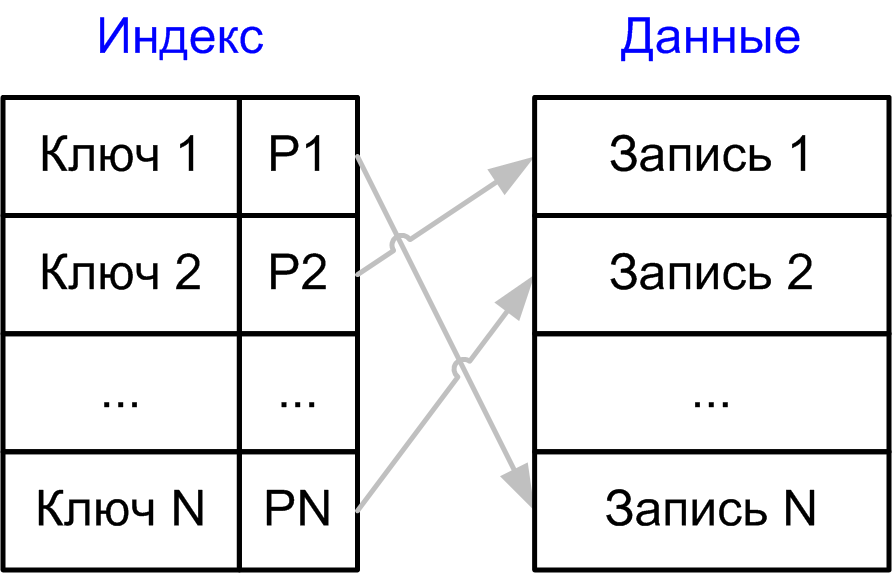
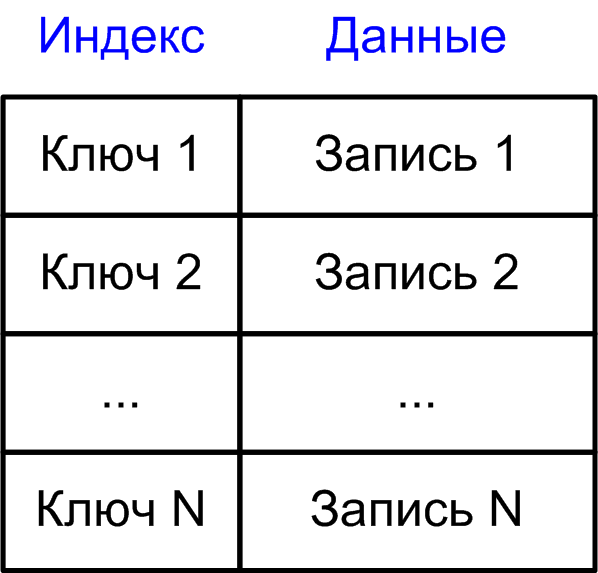
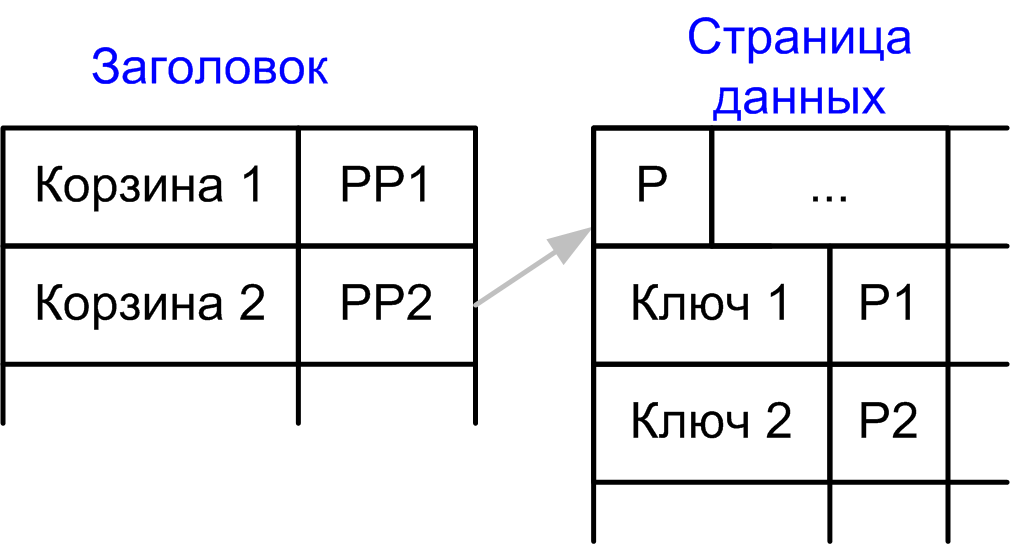
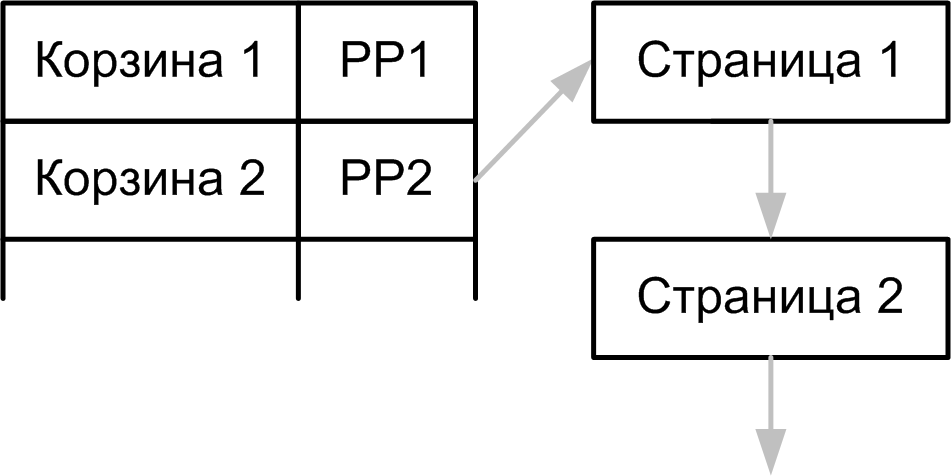
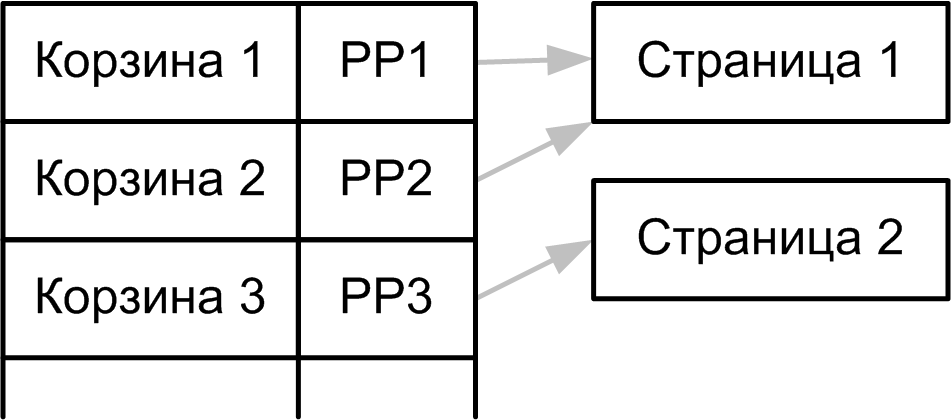
name like 'M343%'
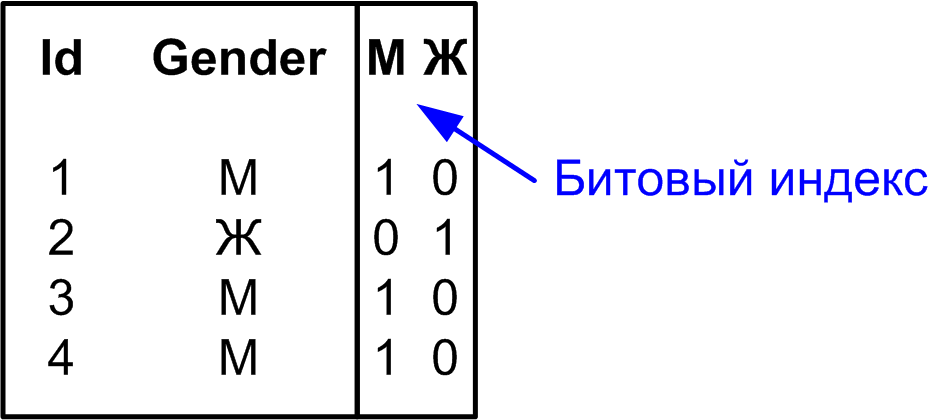


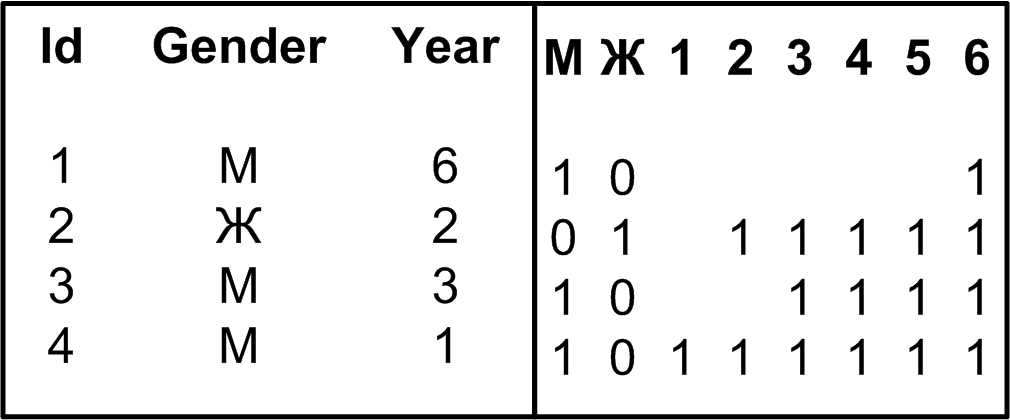
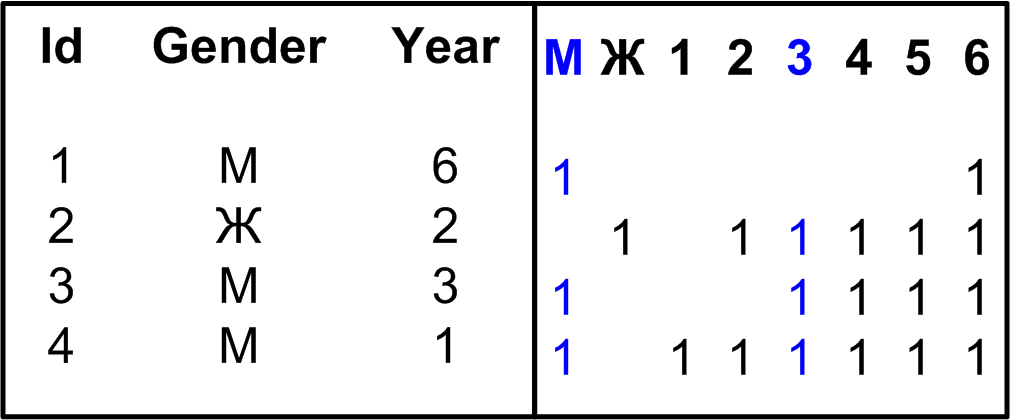
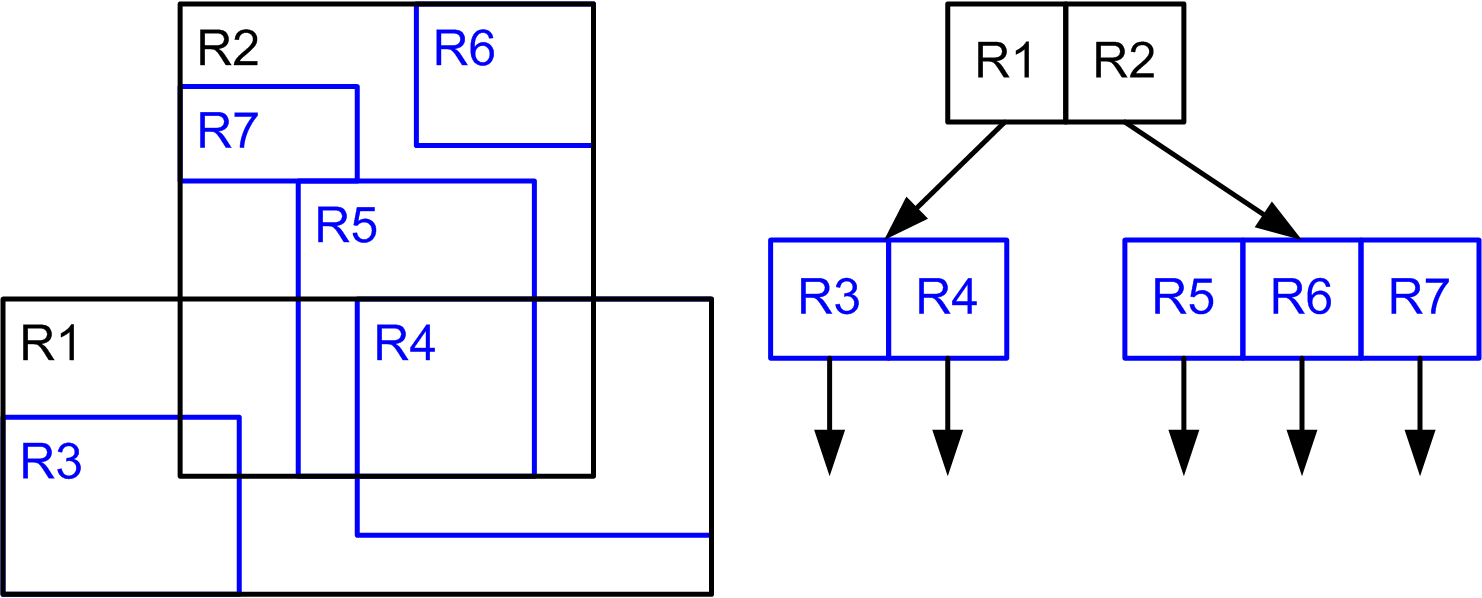
index {имя} {unique|sparse|..}
[using метод] (столбцы)
create {unique|sparse|..} index {имя} on таблица
[using метод] (столбцы)
where условие
drop index {name}
